

Comme vous le savez si vous nous suivez depuis un petit moment, avant d’analyser vos données il faut les préparer, les nettoyer, les enrichir et tutti quanti. Cette phase de data préparation peut représenter jusqu’à 80% (parfois plus) du temps passé par un data analyst sur un projet.
Faire le ménage a toujours provoqué chez moi des crises de « flemmite aigue » (y’a qu’à voir l’état de ma piaule), à tel point qu’il m’arrive régulièrement de faire de l’hyperventilation lorsque je vois un balai, une éponge ou tout autre ustensile de torture quand je vais faire mes courses.

Heureusement, le lave-vaisselle, la machine à laver sont… (on me signale dans l’oreillette que ma vie n’intéresse personne et que les produits ménagers n’intéressent en aucun cas notre audience). Enfin, tout ça pour dire que nettoyer des données c’est souvent long, pénible et répétitif mais heureusement, des solutions existent (parlez-en à un médecin data préparateur). Bref on dispose désormais et depuis peu des Miel, des Dyson et des Bosch du nettoyage de données. Finies les requêtes SQL de 8 kilomètres, finies les macros Excel qui prennent 3h à s’exécuter, finie l’interface austère qui vous hante jusque dans votre sommeil.
Si vous ne voyez toujours pas de quoi je parle, il temps de jeter un coup d’œil à notre livre blanc sur la data préparation.
Et c’est justement sur le thème de la data préparation que, de conférence en conférence, d’évènement en évènement, Tableau ne cesse de teaser la sortie de Maestro devant une foule en délire.

On a vu le Maestro à l’œuvre
Trêve de teasing, on a testé la beta 3 du projet Maestro, un outil de préparation de données développé par Tableau. Si on ne sait pas trop à quelle sauce cela va être intégré aux outils actuels (l’information est encore top secrète) une chose est certaine, la synergie semble intéressante.
Première chose, les connecteurs ! Comme pour le Desktop, pléthore de connecteurs sont d’ores et déjà disponibles.

L’interface semble ergonomique et ressemble pas mal à ce qu’on peut retrouver sur Desktop une fois connecté aux données.
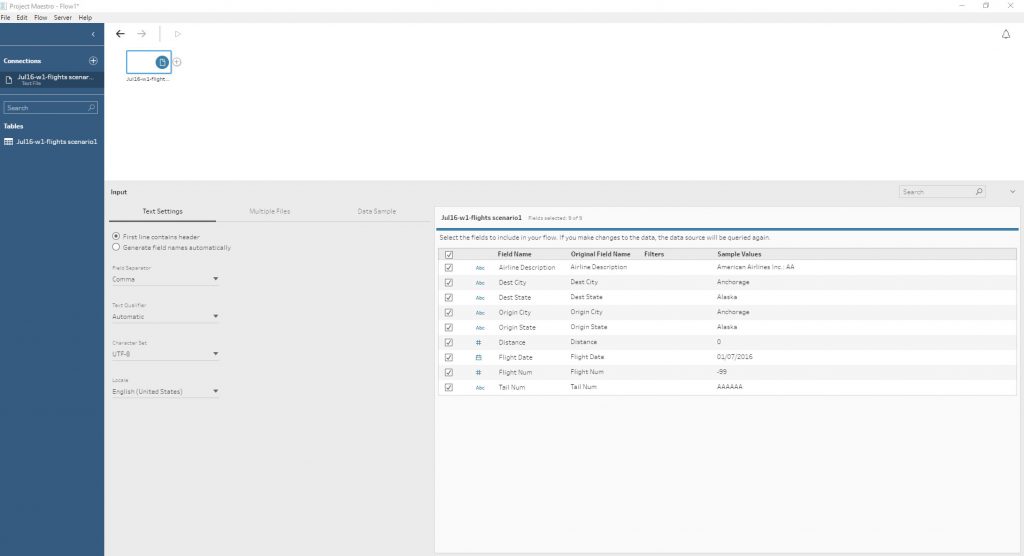
On retrouve donc dans le panneau de gauche nos connexions aux données, en haut un espace de développement de flux (ensemble des opérations d’enrichissement et de nettoyage des données). Et en bas, un panneau de développement.
On peut ensuite ajouter une étape lors de laquelle il sera possible de filtrer et de retraiter les données. Notez dans le panneau du bas un aperçu à la fois des données (types, filtres…) et de leur profil via des histogrammes cliquables permettant de filtrer.
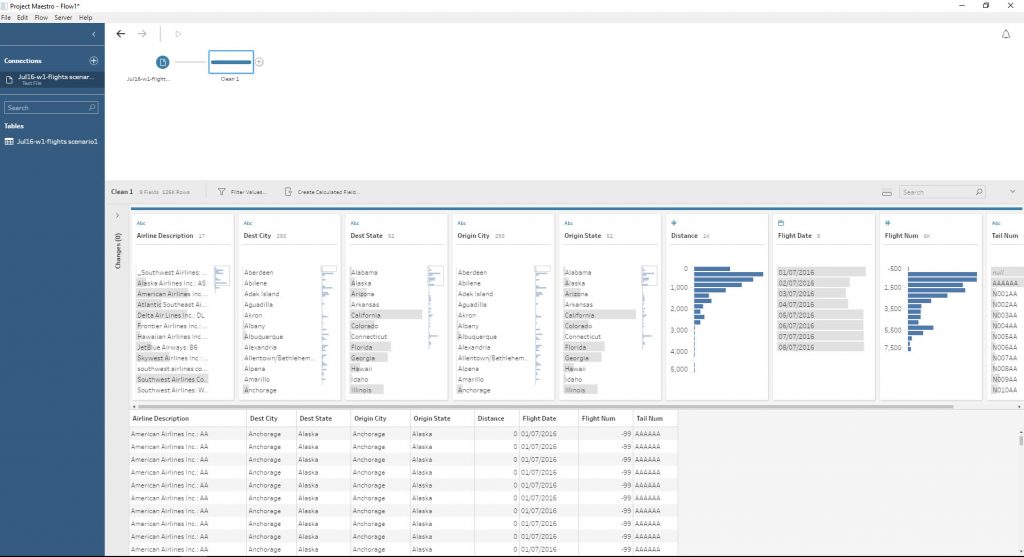
Il est par ailleurs possible de modifier les données directement dans les cases.
L’ensemble des transformations réalisées sont résumées dans un panneau latéral à côté de l’aperçu des données.
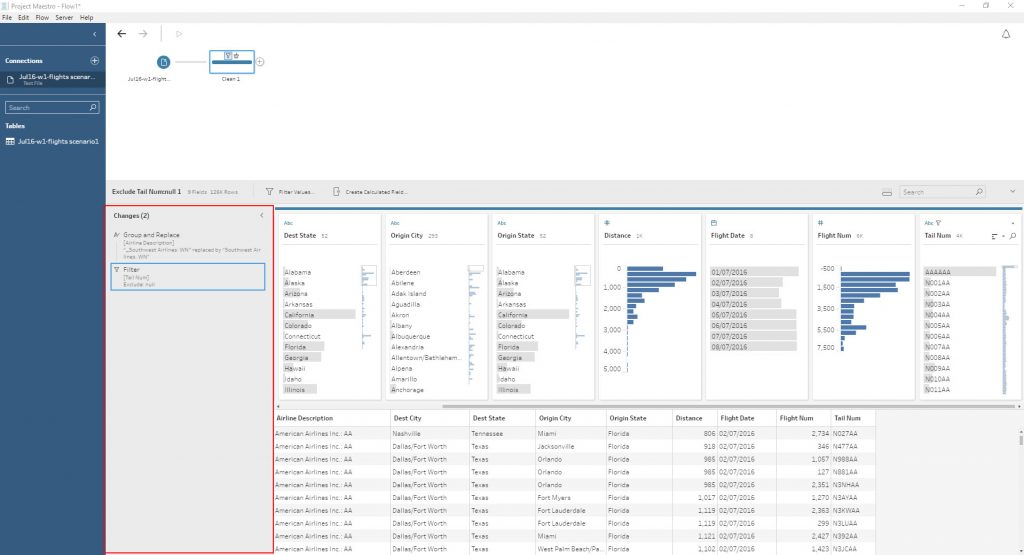
Des fonctionnalités qui sentent bon !
Parmi les fonctionnalités, on retrouve :
- Le filtering
- Le regroupement
- Le cleaning
- Le split
- Les champs calculés
Le filtering, c’est la base, pas besoin de s’y attarder.
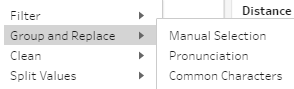
Le regroupement, là on rentre dans une fonctionnalité intéressante proposée par l’outil puisqu’il est possible de faire des remplacements manuels ou par champs calculés mais il est également possible d’utiliser l’équivalent de soundex ! A savoir des regroupements phonétiques permettant rapidement de regrouper des éléments qui sont a priori les mêmes.
Au besoin, on peut manuellement corriger ces regroupements.
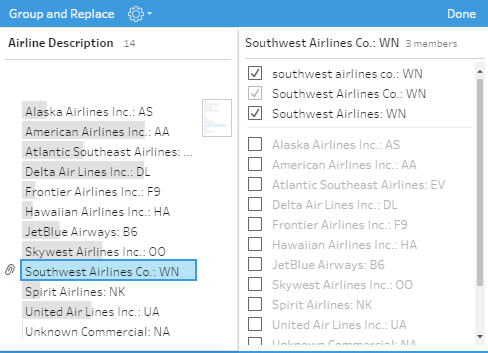
Enfin, il est possible d’effectuer des regroupements par caractères communs automatiquement le tout basé vraisemblablement sur une distance de Levenshtein.
Pour le cleaning, on observe les fonctions les plus usuelles (convertir en majuscules, minuscules, retirer les espaces, la ponctuation…). Ça n’a l’air de rien, mais c’est bien pratique !
Il est également possible de scinder les données, soit de manière automatique, soit avec un délimiteur manuel, une fonction somme toute basique encore une fois, mais qui sauve souvent la vie (ou à défaut nos analyses).
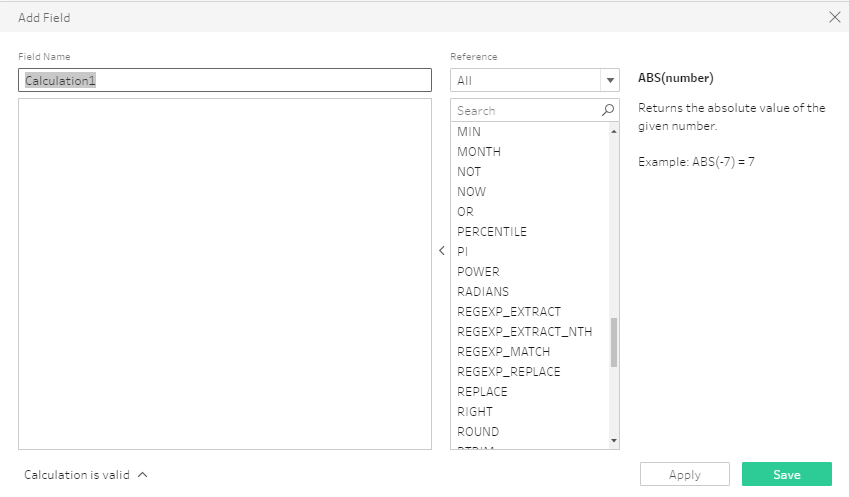
Enfin les champs calculés. Et là, vous ne pouvez pas savoir à quel point j’étais heureux de voir ça. Tableau dispose de beaucoup de fonctions qui nous permettaient déjà de nettoyer ou de préparer les données dans le Desktop (trim, abs, date, replace, right…), mais du coup on se trainait des colonnes inutiles dans notre source de données. Et bien avec Maestro, non seulement toutes ces fonctions sont disponibles mais en plus, on utilise la même syntaxe, c’est pas beau ça ?
Pour terminer, que serait un outil de data préparation si on ne pouvait ni faire de jointure, ni faire d’union ?
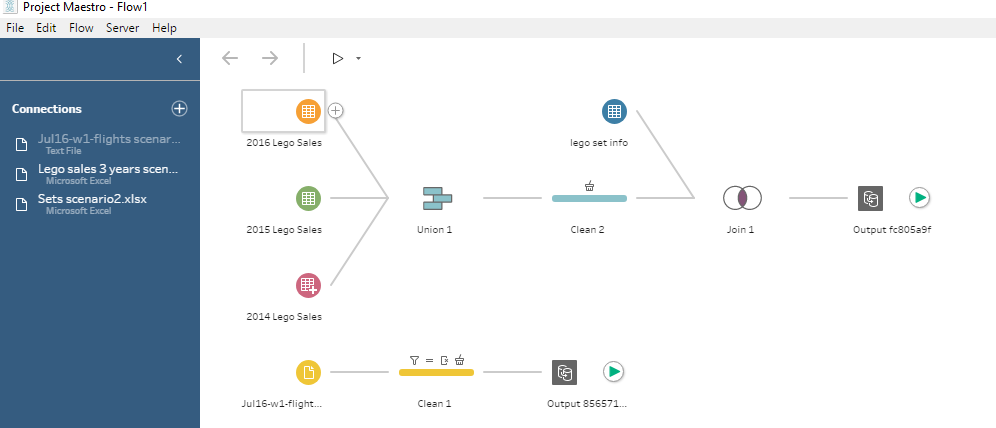
Il est effectivement possible de réaliser ces opérations soit avant, soit après nos différentes étapes de nettoyage. Il nous reste plus qu’à générer notre extrait Hyper et on est bon ! En plus les performances semblent être au rendez-vous ! Et devinez quoi, on peut même générer plusieurs extraits au sein d’un même flux ! Elle est pas belle la vie ?
Vite, la suite !
En définitive, s’il ne s’agit encore que d’une beta, on sent que Tableau a mis l’accent sur l’ergonomie, et la simplicité à l’image du Desktop mais au service de la data préparation cette fois-ci. On prend rapidement l’outil en main, et c’est encore plus vrai si on a fait un peu de Desktop dans sa vie. Les perspectives de synergie avec Tableau Desktop et surtout Tableau Server sont alléchantes, reste à savoir comment vont être intégrés le filtre utilisateur, la publication des flux sur Tableau Server et surtout comment Tableau va-t-il mettre à disposition ce nouvel outil. S’agira-t-il d’un nouveau client ? Sera-t-il intégré à Tableau Desktop ? Ou tout autre chose ? La réponse, on l’espère très vite !



Sections commentaires non disponible.