Ce site stocke des cookies sur votre ordinateur. Nous les utilisons afin de personnaliser votre expérience de navigation ainsi que pour des analyses d'audience.
Eh oui, comme à son habitude, Tableau vient d’annoncer l’arrivée, il y a quelques semaines, de sa dernière version (2019.2) et avec elle, de nouvelles fonctionnalités bien entendu. Parmi toutes... Lire la suite →
Apache Spark est un framework de data processing qui permet de traiter de gros volumes de données. Spark se charge de distribuer le calcul sur plusieurs machines en utilisant principalement... Lire la suite →
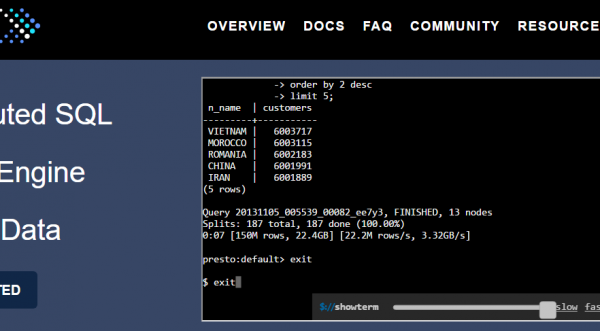
Notre team R&D est allée à la découverte de Presto, un moteur de requête SQL distribué open source, créé par Facebook. Charly Clairmont vous présente ses caractéristiques et vous offre... Lire la suite →
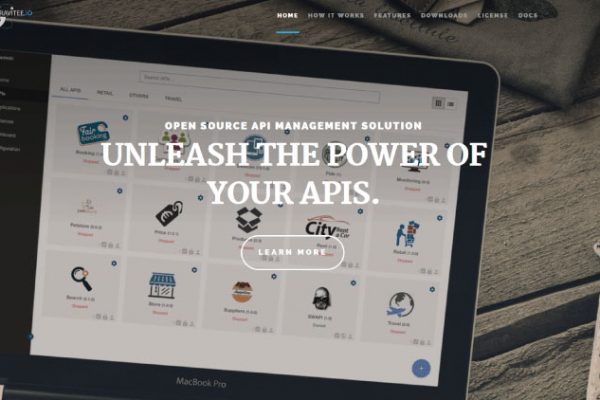
Une fois n'est pas coutume, notre cellule R&D est allée tester un outil qui lui a plu et a décidé de vous en parler ! Aujourd'hui, c'est Gravitee.io, API manager... Lire la suite →
Notre expert Tableau Jonathan Trajkovic est tellement heureux que la version 10.2 propose l'intégration des fichiers géospatiaux qu'il en a fait un article sur son blog, qu'il nous autorise aimablement... Lire la suite →
Alors que la plupart des outils de business intelligence (ETL, reporting, OLAP) sont disponibles en mode clients lourds, l'avènement des interfaces web et du cloud va bientôt changer la donne... Lire la suite →
Pour réaliser notre livre blanc La Data Preparation, un enjeu pour la nouvelle BI, nos experts ont testé les différentes solutions de data preparation du marché. (suite…)